Chapter 2: ArgoCD Overview
When engineers first encounter Argo CD, they often arrive with a mental model shaped by imperative CI systems — pipelines that hold state, queue jobs, and accumulate context over time. Argo CD operates on an entirely different principle. It does not accumulate. It reconciles.
Key Patterns of ArgoCD
The Stateless Reconciler
At its core, Argo CD is a Kubernetes controller. Like all controllers in the Kubernetes ecosystem, it runs a continuous reconciliation loop: observe the current state of the cluster, compare it against the desired state declared in Git, and act to close any gap. No step in this loop requires knowledge of a previous loop iteration.
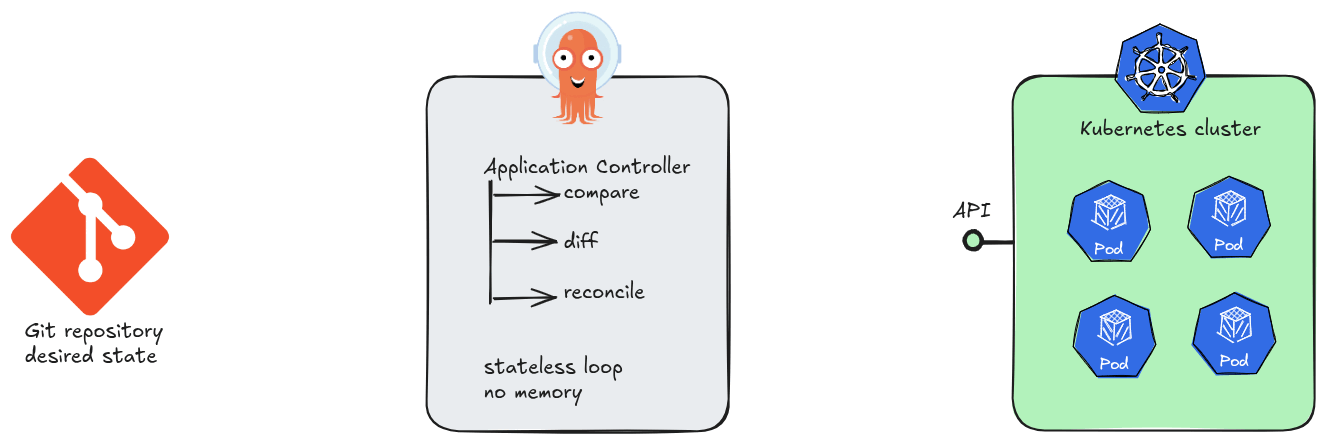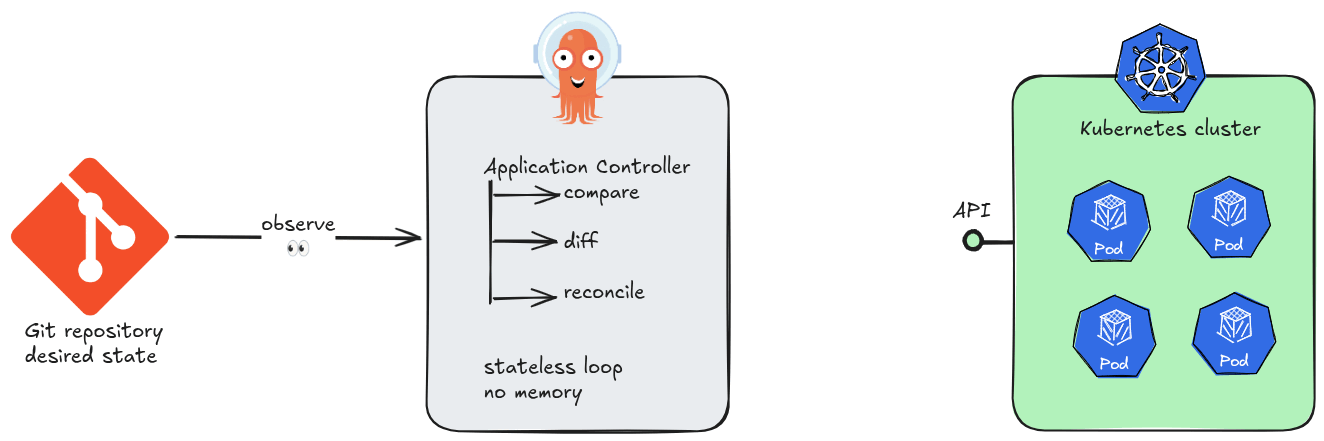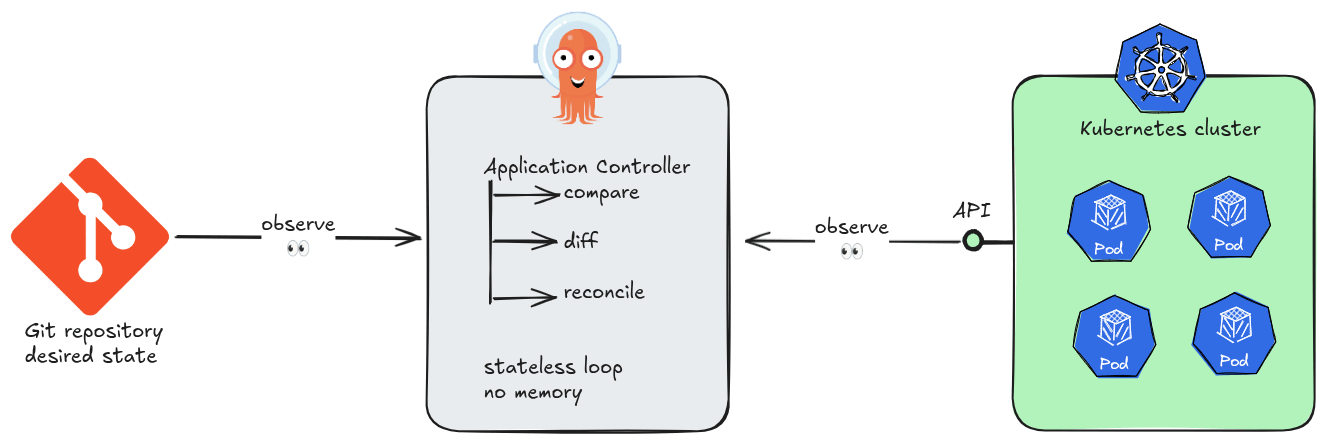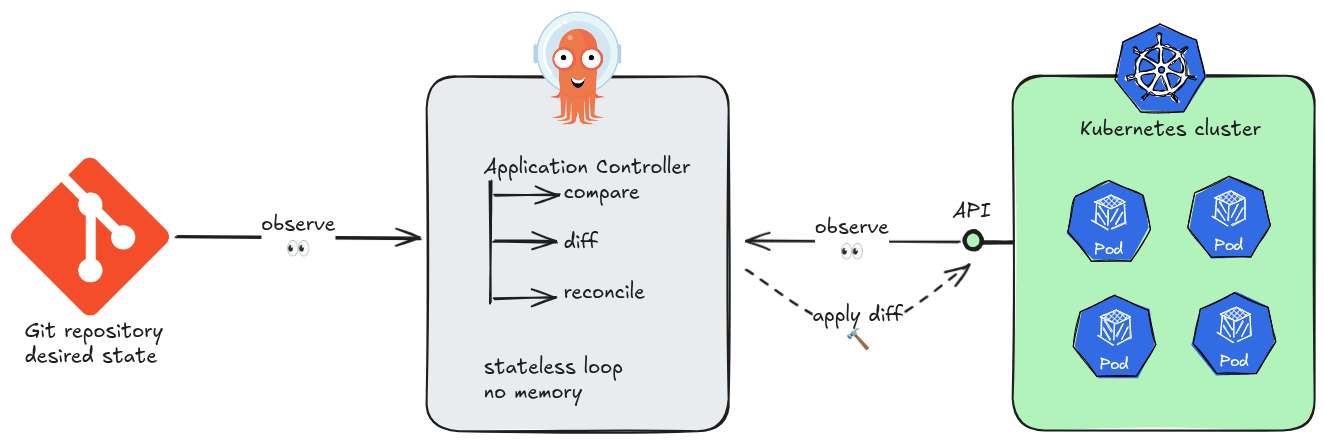
This is the essence of stateless design. Argo CD’s application controller holds no in-memory queue of “what happened before.” Each sync cycle begins by reading directly from two authoritative sources of truth: the Git repository and the live Kubernetes API. If the controller pod is killed and restarted, it resumes reconciling as if nothing happened — because nothing meaningful was lost.
The practical consequences of statelessness are significant. Argo CD instances can be scaled horizontally, replaced, or upgraded without coordination ceremonies. A new replica does not need to “catch up” — it simply starts reconciling. There is no master node, no write-ahead log to replay, no session to hand off.
Note on persistence
Argo CD does write records — application objects, sync history, RBAC configuration — to Kubernetes resources (primarilyConfigMapsandSecrets). But these are durable Kubernetes objects, not application memory. The controller itself remains stateless; its data lives inetcd, not in the process.
Declarative Self-Management
A system that enforces GitOps for application workloads should, in principle, manage its own
configuration the same way. Argo CD supports exactly this: its own operational configuration —
repositories, clusters, projects, and even its own Application resources — can be expressed
declaratively and stored in Git. This is often referred to as “Recursive GitOps” or the “App-of-Apps” pattern. In this setup, Argo CD treats itself as just another application, closing the loop between the desired state in Git and the live state of the cluster.
Extensibility
Argo CD provides a flexible framework that adapts to diverse engineering requirements. This extensibility ensures that the platform can manage various configuration formats and integrate with existing infrastructure without requiring significant architectural changes.
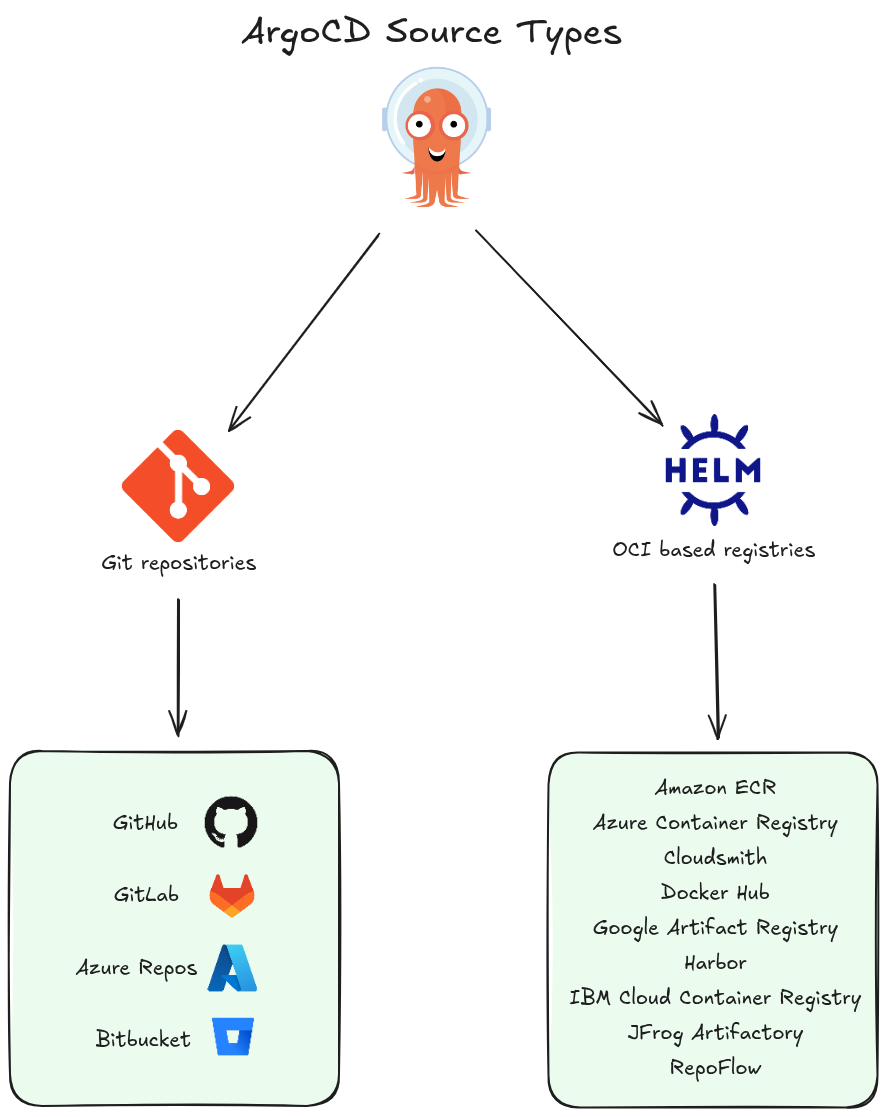
Multiple Source Integration
Argo CD supports multiple repository types, allowing teams to source GitOps content from more than just standard Git providers. It natively connects to Helm repositories and OCI registries, providing the flexibility to pull configurations from the specific version control or storage systems that an organization already utilizes.
Native Templating Support
To simplify the management of Kubernetes manifests, Argo CD includes built-in support for popular templating tools such as:
The platform automatically recognizes these formats and renders them into valid Kubernetes YAML, allowing developers to use their preferred configuration languages without manual intervention.
Custom Extensions
For specialized needs, users can add custom tools to the Argo CD environment. These user-defined integrations allow the platform to interact with external resources or apply advanced logic during the rendering process. This capability ensures that Argo CD can scale to meet unique organizational requirements and complex deployment scenarios.
ArgoCD Architecture
Under the hood, ArgoCD uses microservices architecture in it’s design, where each component runs as a separate standalone service responsible for a specific task.
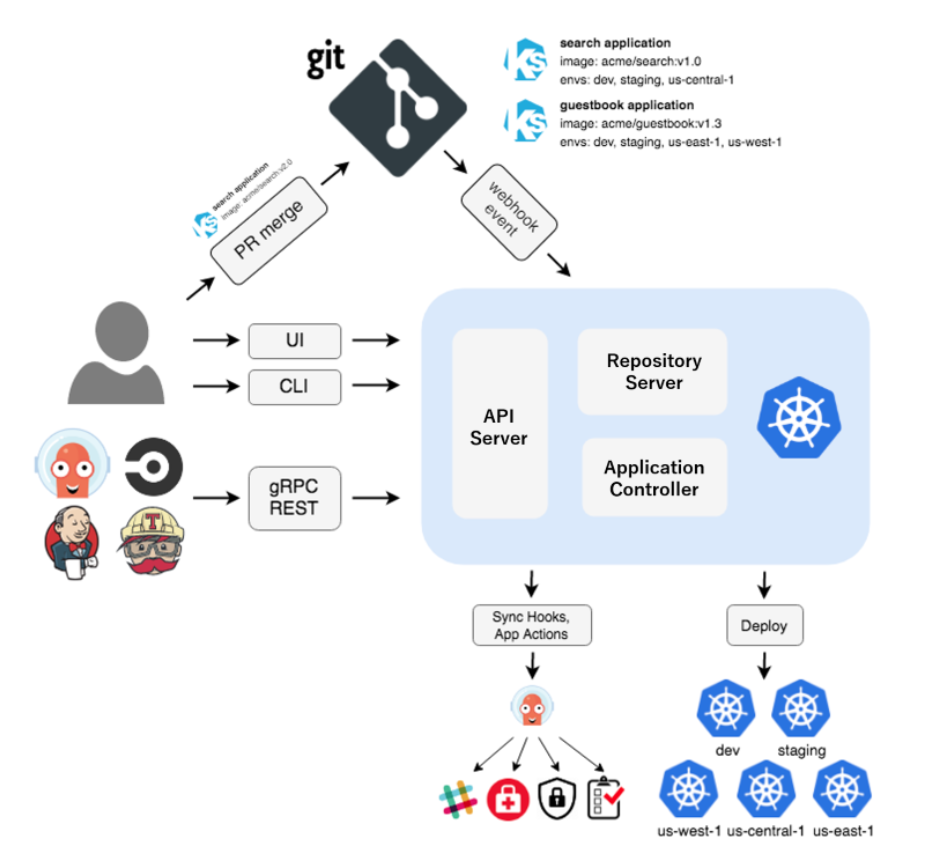 Image source: Official ArgoCD Docs Website
Image source: Official ArgoCD Docs Website
All ArgoCD internal components can be categorized into the following 4 logical sections:
- UI: The entry point where users interact with the system via the Web interface or CLI.
- Application: The logic layer that bridges the UI with backend operations, providing the necessary APIs and management capabilities.
- Core: The “brain” of the operation, containing the Kubernetes controllers and GitOps logic that synchronize desired and live states.
- Infra: The underlying dependency layer, including external tools and databases that provide the foundational infrastructure for Argo CD to run.
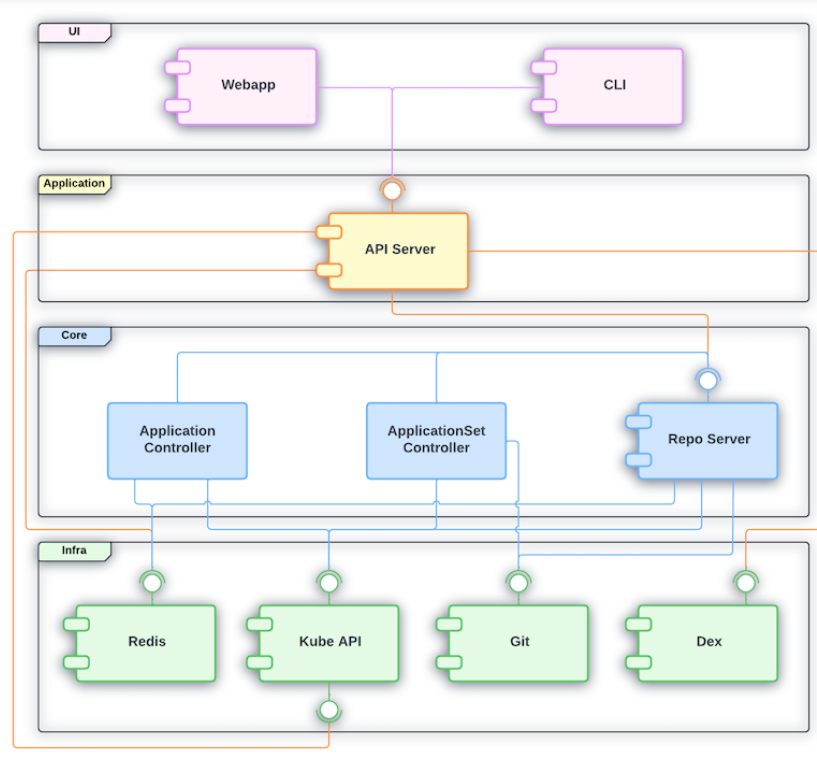 Image source: Official ArgoCD Docs Website
Image source: Official ArgoCD Docs Website
If we look closely under the hood of the ArgoCD engine we will see the following core components:
API Server
API Server (argocd-server)
The central control plane — exposes a gRPC/REST API consumed by the Web UI, CLI, and CI/CD systems. Handles authentication, RBAC enforcement, and delegates operations to other components.
Repository Server
Repository Server (argocd-repo-server)
Manages Git repository interactions. It clones repos, renders manifests (Helm, Kustomize, Jsonnet, plain YAML), and caches results. It’s stateless and can be scaled horizontally.
Application Controller
Application Controller (argocd-application-controller)
The heart of ArgoCD — a Kubernetes controller that continuously watches live cluster state vs. desired Git state. It detects drift (OutOfSync) and triggers sync operations. Runs as a StatefulSet for sharding support.
ApplicationSet Controller
ApplicationSet Controller (argocd-applicationset-controller)
Automates the creation of multiple Application resources using generators (Git, cluster, matrix, list, etc.). Useful for multi-cluster or multi-tenant deployments.
Dex
Dex (argocd-dex-server)
An embedded OIDC identity provider used for SSO integration. Bridges ArgoCD with external identity providers like GitHub, LDAP, SAML, and Google.
Redis
Redis (argocd-redis)
Used as a caching layer and for storing temporary state. The API Server and Application Controller rely on it heavily to reduce load on the Kubernetes API and Git repos.
Notifications Controller
Notifications Controller (argocd-notifications-controller)
Sends alerts and notifications (Slack, email, PagerDuty, etc.) based on Application events like sync failures or health changes.
The Application Controller + Repo Server pair is the core engine — everything else supports observability, access control, or automation around them.
How ArgoCD Components Interact
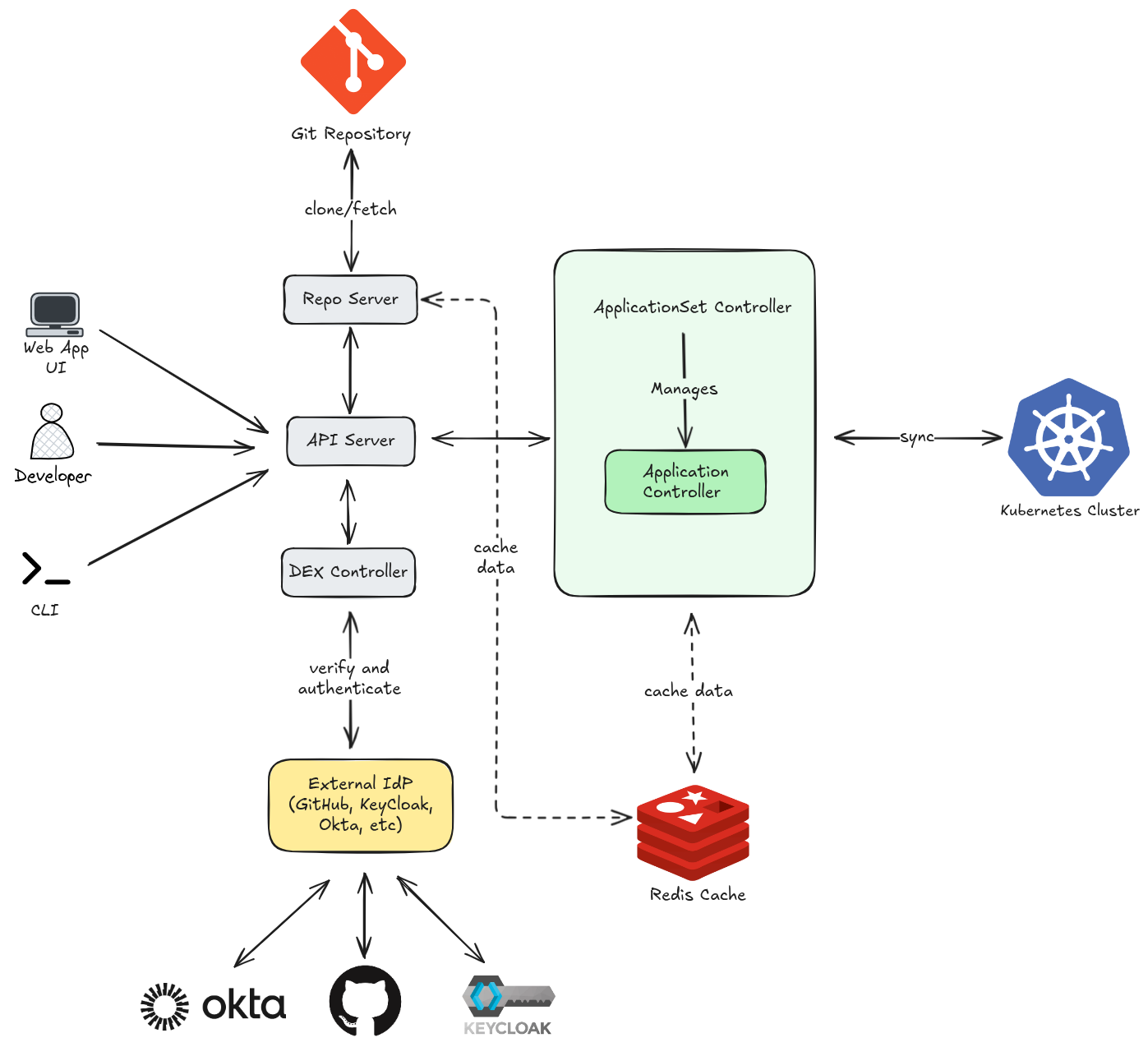
- You (or a CI pipeline) sends a request — e.g. “sync this app” via UI, CLI, or webhook
- API Server authenticates you via DEX component, checks RBAC, then forwards the intent to the Application Controller or ApplicationSet Controller
- Application Controller figures out what needs to change and applies it
- Kubernetes Cluster receives the final manifests and runs them
When the API Server needs to know what the app should look like, it asks the Repo Server:
- API Server delegates manifest rendering to the Repo Server
- Repo Server clones/fetches the Git repo, renders the manifests (Helm/Kustomize/YAML)
- Git Repo is the source of truth — the desired state lives here
The Repo Server also caches rendered manifests to avoid hitting Git on every request.
The Application Controller constantly compares live state (cluster) vs desired state (Git):
- It caches cluster state and sync results in Redis to avoid hammering the Kubernetes API
- Redis also stores temporary session data for the API Server
- Without Redis, every comparison would require a full cluster re-query
Putting It All Together — A Sync Example
| Step | What Happens |
|---|---|
| 1 | You click “Sync” in the UI |
| 2 | API Server authenticates + authorizes you |
| 3 | API Server asks Repo Server for the latest manifests from Git |
| 4 | Repo Server fetches from Git and renders them |
| 5 | Application Controller compares rendered manifests vs live cluster state (using Redis cache) |
| 6 | Controller applies the diff to the Kubernetes Cluster |
| 7 | Cluster state is updated and cached back in Redis |
The key insight: Git is always the source of truth. ArgoCD’s entire job is to make the cluster match what Git says — every arrow in the diagram serves that goal.